Skip to main content
Search
Search This Blog
SEO Mania
Pages
Home
More…
Posts
Showing posts from March, 2014
Show All
March 28, 2014
What is the Best way to differentiate between ccTLD’s
March 28, 2014
How to Markup Videos on your website
March 25, 2014
How to judge that with which algorithm your website been hit or penalized
March 24, 2014
Can sites do well without using spammy techniques?
March 21, 2014
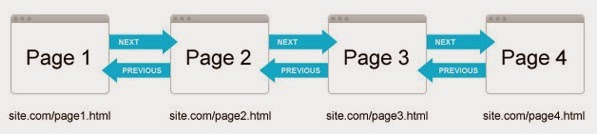
Conquering Pagination – A Guide to Consolidating your Content
March 21, 2014
What FACEBOOK and GOOGLE are Hiding from world.
March 20, 2014
Can I place multiple breadcrumbs on a page?
March 19, 2014
How To Create Amazing About Us Pages
March 19, 2014
SEO copywriting tips How to write a top converting about us page
March 18, 2014
What should sites do with pages for products that are no longer available?
March 14, 2014
Is there a way to tell Google about a mobile version of a page?
March 10, 2014
How content should be designed to get rank higher?
March 05, 2014
What is a "Paid Link" - From Matt Cutts
Newer Posts
Older Posts
Home